科普文章 - 字符串技术巡礼
字符串技术巡礼
前言
本文主要内容是一些许多人不怎么会的字符串组合算法,而主要内容基本可以理解为论文导读。笔者认为,许多技术是可以被放入(甚至可以说很适合被放入)OI 的框架中的,只是由于这些技术引入 OI 的时机较晚,因此尚未得到普及。
1. 记号与约定
字符集是一个全序集,默认是有限的,记为 $\Sigma$。
字符串是由若干字符(字符集的元素)构成的序列,字符串的集合记为 $\Sigma^*$,一般用小写字母 $u,v,w$ 等表示字符串,也有时用大写字母 $S,T$ 表示字符串。
字符串 $w$ 的长度定义为包含的字符数量,记为 $|w|$。
若 $|w|=0$,则定义 $w$ 为空串,记为 $\varepsilon$,空串是唯一的。
记 $\Sigma^+=\Sigma^* - \{\varepsilon\}$。
记 $w_i$ 表示 $w$ 的第 $i$ 个字符。
记 $w[l,r]$ 或 $w[l\ldots r]$ 表示由 $w_l,\ldots,w_r$ 组成的字符串,称为 $w$ 的一个子串。当 $l>r$ 时定义 $w[l,r]=\varepsilon$。
称 $w[1,i]$ 为 $w$ 的一个前缀,$w[i,n]$ 为 $w$ 的一个后缀。
若 $w$ 的一个子串(前缀/后缀)不等于 $w$,则称其为真子串(真前缀/真后缀)。
若 $u$ 是 $v$ 的前缀,记作 $u\sqsubseteq v$;若 $u$ 是 $v$ 的真前缀,记作 $u\sqsubset v$。
对于两个串 $u,v$,$u+v$ 或 $uv$ 定义为一个长度为 $|u|+|v|$ 的串 $w$,其中 $w_i=u_i (i\leq |u|), w_i=v_{i-|u|} (i>|u|)$,称为 $u,v$ 的拼接。
定义 $\operatorname{Rev}(u)$ 为一个长度为 $|u|$ 的串 $v$,其中 $v_i=u_{|u|-i+1}$。
若 $w=\operatorname{Rev}(w)$,则称 $w$ 为回文串。
定义 $\operatorname{LCP}(u,v)$ 表示最大的 $i$ 使得 $i\leq \min(|u|,|v|)$ 且 $u[1,i]=v[1,i]$。
定义 $\operatorname{LCS}(u,v)$ 表示最大的 $i$ 使得 $i\leq \min(|u|,|v|)$ 且 $u[|u|-i+1,|u|]=v[|v|-i+1,|v|]$。
对于两个串 $u,v$,我们称 $u$ 的字典序比 $v$ 小,或 $u<v$,当且仅当以下条件满足至少一个:
$u\sqsubset v$;
存在一个 $1\leq i\leq \min(|u|,|v|)$ 使得 $u[1,i-1]=v[1,i-1], u_i<v_i$,将这种情况记为 $u\lhd v$。
2. 前置知识
并非在每种技术中都会用到全部的前置知识,但这些是字符串理论的基础,几乎都在 NOI 大纲内。
字典树
不再赘述。
自动机
不再赘述。
我们通常考虑有限状态自动机,其中分为确定性有限状态自动机和非确定性有限状态自动机。字典树也可以看作一个自动机。
Border 和周期
对于字符串 $w$,若整数 $0<p\leq |w|$ 满足 $w_i=w_{i+p} (i\leq |w|-p)$,则称 $p$(或 $w[1,p]$)是 $w$ 的一个周期。
若整数 $0\leq p<|w|$ 满足 $w[1,p]=w[|w|-p+1,|w|]$,则称 $p$(或 $w[1,p]$)是 $w$ 的一个 Border。
结论:$p$ 是 $w$ 的周期当且仅当 $|w|-p$ 是 $w$ 的 Border。
定理(周期引理,Periodicity Lemma):若 $p,q$ 都是 $w$ 的周期,且 $p+q\leq |w|+\gcd(p,q)$,则 $\gcd(p,q)$ 是 $w$ 的周期。
弱周期引理(Weak Periodicity Lemma,WPL)是一个弱化版本,即将上述条件替换为 $p+q\leq |w|$。
结论:$w$ 的长度在 $(x,2x]$ 中的所有 Border 构成一个等差数列。对于周期,有类似的结论。
我们可以 $O(|w|)$ 地求出 $w$ 的全部周期或 Border。
Aho-Corasick 自动机
对于一个字符串集合 $W=\{w_1,\ldots,w_k\}$,令 $W_p$ 是每个 $w_i$ 的所有前缀构成的集合。建立 $W_p$ 的字典树 $T$,字符串 $u$ 对应的树上结点记为 $f(u)$。
对于树上结点 $x$,设 $u=f^{-1}(x)$,$v$ 是 $u$ 的最长的属于 $W_p$ 的真后缀,定义 $B_x=f(v)$。数组 $B$ 称为失配数组。以 $B_x$ 为 $x$ 的父结点将形成一棵树 $T’$,称为失配树。
令:
其中 $ch(x,c)$ 表示 $T$ 上与 $x$ 之间边的字符为 $c$ 的子结点。
以 $tr$ 为转移,这得到了一个自动机,称为 $W$ 的 Aho-Corasick 自动机,简称 AC 自动机(ACAM)。
当 $W=\{w\}$ 时,这种特化的单串 AC 自动机称为 KMP 自动机,失配数组的含义为 $w$ 的每个前缀的最长 Border 位置。
结论:设串 $u$ 在 $W$ 的 AC 自动机上运行到点 $x$,则 $u$ 的最长的属于 $W_p$ 的后缀为 $f^{-1}(x)$。
结论:$W_p$ 中所有 $f^{-1}(x)$ 的后缀恰好是所有 $f^{-1}(y)$,$y$ 取遍 $x$ 在失配树上的祖先。
我们可以 $O(\sum_{w\in W}|w|\log |\Sigma|)$ 地建立 $W$ 的 ACAM(事实上,是 $O(\sum_{w\in W}|w|+|T|\log |\Sigma|)$,其中 $|T|$ 是字典树结点数)。
后缀数组
定义排列 $\operatorname{SA}_w(1),\ldots,\operatorname{SA}_w(|w|)$ 表示:$w$ 的第 $i$ 小的非空后缀为 $w[\operatorname{SA}_w(i),|w|]$。
定义排列 $\operatorname{ISA}_w(1),\ldots,\operatorname{ISA}_w(|w|)$ 为 $\operatorname{SA}_w(1),\ldots,\operatorname{SA}_w(|w|)$ 的逆排列。有时 $\operatorname{ISA}$ 也写作 $\operatorname{Rank}$。
对于 $2\leq i\leq |w|$,定义 $\operatorname{Height}_w(i)=\operatorname{LCP}(w[\operatorname{SA}_w(i-1),|w|],w[\operatorname{SA}_w(i),|w|])$。
结论:$\operatorname{LCP}(w[\operatorname{SA}_w(x),|w|],w[\operatorname{SA}_w(y),|w|])=\min_{i=x+1}^y \{\operatorname{Height}_w(i)\}$,其中 $x<y$。
我们可以 $O(|w|)$ 地建立 $w$ 的 SA,但是常用算法是 $O(|w|\log |w|)$ 的。
后缀树
设 $w$ 的所有后缀组成的集合为 $W_s$,$W_s$ 的字典树称为 $w$ 的后缀字典树。
将字典树上所有度数为 $2$ 的非根结点缩去(缩到边上),得到的树称为 $w$ 的隐式后缀树。
如果只缩那些不对应 $w$ 的后缀的结点,那么得到的树称为 $w$ 的后缀树(注意,这只是本文的约定)。
也有一种说法是在 $w$ 的末尾加上一个不同于 $w$ 中任何字符的字符 $\$$,得到 $\hat w$,其(按上述定义的)后缀树称为 $w$ 的(显式)后缀树。
类似我们在 AC 自动机中所做的,可以求出失配数组 $B_x$,在这里称为后缀链接,记为 $\operatorname{lk}(x)$。
结论:后缀树结点数为 $O(|w|)$。
后缀自动机
能接收 $w$ 所有子串的最小 DFA,称为 $w$ 的后缀自动机(SAM)。
记 $\operatorname{Endpos}(u)$ 和 $\operatorname{Startpos}(u)$ 分别表示 $u$ 在 $w$ 中作为子串出现的左端点集合和右端点集合。
结论:后缀自动机状态数和转移数为 $O(|w|)$。
结论:后缀自动机的每个结点代表一族 $\operatorname{Endpos}$ 相等的子串,它们是其中最长者的最长的一部分后缀。
结论:$\operatorname{Endpos}$ 集合只有不交和包含两种关系,以此可以建出一棵树,称为 SAM 的树结构,这棵树等价于反串 $\operatorname{Rev}(w)$ 的后缀树。
我们可以 $O(|w|\log |\Sigma|)$ 地建立 $w$ 的后缀树和 SAM。
回文树 / 回文自动机
将 $w$ 的每个回文子串对应到一个结点,另外建立两个特殊结点分别称为奇根和偶根。令字符串 $u$ 对应的结点为 $f(u)$,则:$|u|=1$ 时 $f(u)$ 的父结点为奇根;$|u|=2$ 时 $f(u)$ 的父结点为偶根;否则 $f(u)$ 的父结点为 $f(u[2,|u|-1])$。这将得到一个有两个根的森林结构,称为回文树。
对于一个回文串 $u$,将其长度为 $\lceil\frac{|u|}{2}\rceil$ 的后缀称为其半串。回文树可以看作是所有回文子串对应的半串的 Trie(但对长度为奇数和偶数的回文串有特殊的标识分开),于是我们可以构造它的 ACAM,这样构造出的自动机结构称为回文自动机(PAM),类似可以定义失配指针 $B_x$ 和失配树。
结论:回文串的所有 Border 都是回文串,回文子串 $u$ 的最长 Border 等于其最长回文真后缀,为 $f(u)$ 在回文自动机上失配指针指向的结点对应的回文子串。
我们可以 $O(|w|\log |\Sigma|)$ 地建立 $w$ 的 PAM。
Manacher 算法
我们可以 $O(|w|)$ 地对于每个 $i\in [1,|w|]$ 求出最大的 $j$ 使得 $w[i-j+1,i+j-1]$ 是回文串。
Z 函数
我们可以 $O(|w|)$ 地对于每个 $i\in [1,|w|]$ 求出 $\operatorname{LCP}(w,w[i,|w|])$。
3. 区间 Border / 基本子串字典
论文:陈孙立,子串周期查询问题的相关算法及其应用,IOI 2019 集训队论文集
基本子串字典被引入 OI 可能主要是为了解决区间 Border 问题,即:
- 给定一个字符串 $w$,有 $q$ 次询问,每次给定一个 $w$ 的子串 $w[l,r]$,求它的 Border 集合。
根据 Border 的相关知识,我们知道 $w[l,r]$ 的 Border 可以表示成 $O(\log(r-l+1))$ 个等差数列的(不相交)并,我们希望得到一种 $O(\log(r-l+1))$ 的算法求出这些等差数列(作为 Border 集合的一种表示)。
- 定义:考虑 $w$ 的所有长度为 $2^k$ 的子串 $w[i,i+2^k-1]$,给予它们标号 $N_k(i)$ 使得 $N_k(i)\leq N_k(j) \iff w[i,i+2^k-1]\leq w[j,j+2^k-1]$,且 $N_k(i)$(关于 $i$)的值域是连续的正整数。对于所有 $k$,这一系列标号数组 $N_k$ 称为 $w$ 的基本子串字典。
对于任意字符串 $w$,我们之前已经给出了一个结论:$w$ 的长度在 $(x,2x]$ 间的 Border 构成等差数列。于是现在我们的想法就是把子串 $w[l,r]$ 的 Border 长度划分为 $(1,2],(2,4],(4,8]$ 这些由 $2$ 的幂为端点的区间,每一段区间内 Border 都占据一个等差数列。现在我们考虑如何求长度处在 $(2^k,2^{k+1}]$ 中的所有 Border。
引理 1:对于字符串 $u,w$,如果 $2\times |u|\ge |w|$,则 $u$ 在 $w$ 中作为子串出现时的左端点构成了一个等差数列。
证明:如果 $u$ 在 $w$ 中的出现次数不超过 $2$,则结论显然。下面考虑 $u$ 出现至少三次的情形。
考虑任意三次相邻的 $u$ 的出现,设其左端点分别是 $l,l+p_1,l+p_1+p_2$,由 $2|u|\ge |w|$ 可知 $p_1+p_2\leq |u|$,那么因为 $p_1,p_2$ 都是 $u$ 的周期,所以根据 WPL 可知 $p_0=\gcd(p_1,p_2)$ 也是 $u$ 的周期。考虑这三次出现的并,即 $w[l,l+p_1+p_2+|u|-1]$,由 $p_0$ 是 $u$ 的周期不难得到 $p_0$ 是 $w[l,l+p_1+p_2+|u|-1]$ 的周期,从而 $l+p_0$ 或 $l+p_1+p_0$ 也是合法的(即 $u$ 出现的)左端点,而这与 $p_1\ne p_2$ 的假设矛盾(其中至少一个不等于 $p_0$),因此原命题得证。
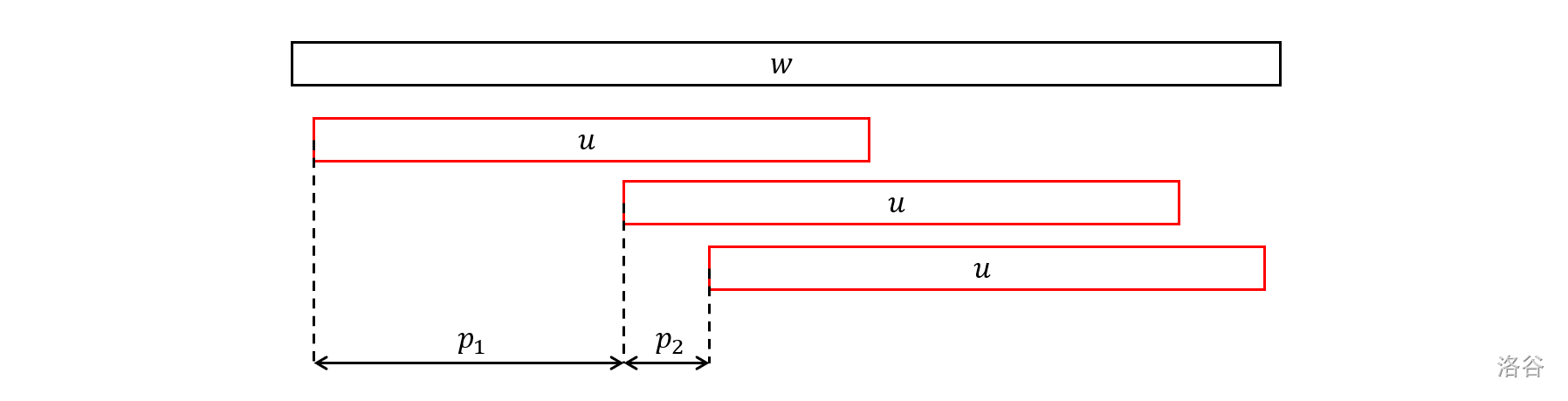
设 $p$ 是 $u$ 的最小周期。注意到 $p_1+p_2\leq |u|\longrightarrow \min(p_1,p_2)\leq \frac{|u|}{2}$,所以其中必有一个 $p$ 的倍数,那么按照和上面类似的推理过程可以得到下述推论:
- 推论:在上述引理的条件下,如果 $u$ 在 $w$ 中出现至少三次,则这些出现的左端点构成的等差数列公差等于 $u$ 的最小周期。
让我们回到需要求解的问题:求出 $w[l,r]$ 的长度在 $(2^k,2^{k+1}]$ 中的所有 Border。
考虑 $u=w[l,l+2^{k+1}-1], u_0=[l,l+2^k-1], v=w[r-2^{k+1}+1,r], v_0=w[r-2^k+1,r]$,设 $u_0$ 在 $v$ 中的出现位置集合为 $S_1$,$v_0$ 在 $u$ 中出现位置集合为 $S_2$。那么每有一个 $(2^k,2^{k+1}]$ 中的 Border $x$,就必有对应的一个 $S_1$ 及 $S_2$ 中的元素(即由 $x$ 是 Border 蕴含的 $u_0$ 在 $v$ 中的出现以及 $v_0$ 在 $u$ 中的出现),因此将 $S_1,S_2$ 平移后求交就是 Border 集合了。
根据引理 1,$S_1,S_2$ 都是等差数列,但下面我们要得出一个更强的结论:
引理 2:如果 $|S_1|>2$ 且 $|S_2|>2$,则它们的公差相等。
证明:根据上一个引理及其推论,可知此时 $S_1$ 的公差等于 $u_0$ 的最小周期 $p_u$,$S_2$ 的公差等于 $v_0$ 的最小周期 $p_v$,假设 $p_u\ne p_v$。
以 $p_u>p_v$ 为例,$p_u
这说明 $p$ 也是 $u_0[|u_0|-p_u+1,|u_0|]$ 的周期,从而是 $u_0$ 的周期,这与 $p_u$ 的最小性矛盾。
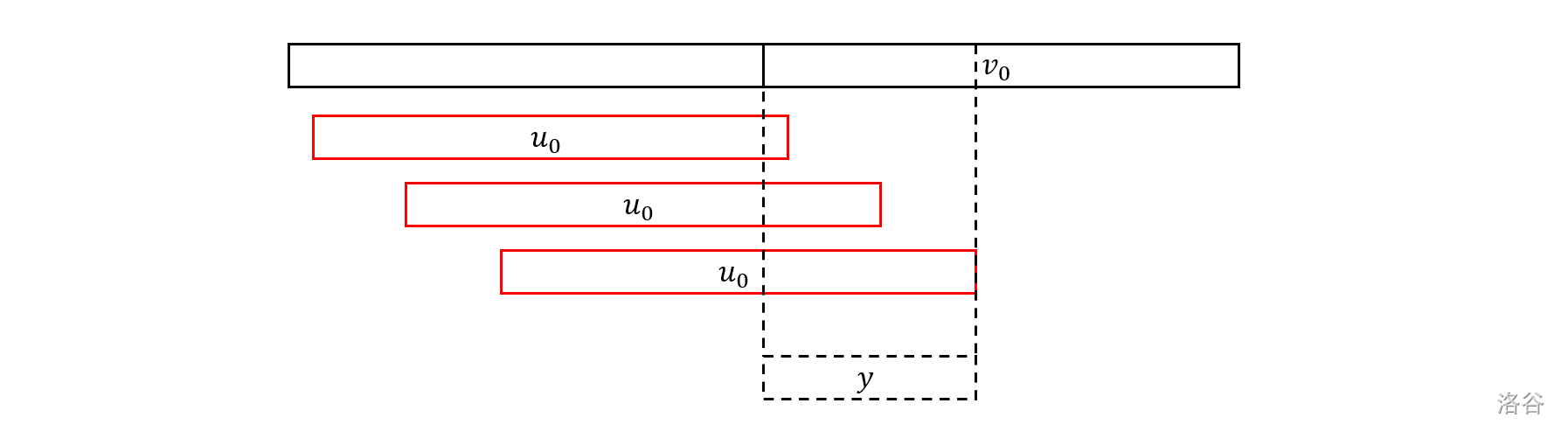
于是如果我们已知 $S_1,S_2$,就可以 $O(1)$ 求出这两个等差数列的交(如果其中有一个大小不超过 $2$ 则平凡,否则公差相同容易合并)。下面考虑如何 $O(1)$ 求出 $S_1,S_2$。
这就要用到基本子串字典。以 $S_1$ 为例,我们实际上要找到以 $[r-2^{k+1}+1,r-2^k]$ 开头的长度为 $2^k$ 的子串中有哪些等于 $u_0$。而对于一个等差数列,只需要找到首项、末项和第二项就可以得到整个数列,所以我们只需找到使得 $i\in [r-2^{k+1}+1,r-2^k]$ 且 $N_k(i)=N_k(l)$ 的 $i$ 的最小、次小、最大值即可。
将序列以 $2^k$ 为块长分块,则每一块中使得 $N_k(i)=N_k(l)$ 的 $i$ 都应该是个等差数列(因为总可以表示成“某个子串的长度在 $(2^k,2^{k+1}]$ 中的 Border 集合”的形式),设第 $x$ 块中这个等差数列是 $s(l,x)$,查询时我们只需求出至多两块(因为查询区间长度是 $2^k$)然后将它们的结果拼接即可。那么某一个 $s(l,x)$ 如何查询呢?这可以使用哈希表完成:因为 $s(l,x)\ne \varnothing$ 的 $(l,x)$ 只有 $O(n)$ 种(因为总共只有 $n-2^k+1$ 个长度为 $2^k$ 的子串)。
于是,我们 $O(\log(r-l+1))$ 地支持了查询区间 Border 集合,将哈希表换为二分可以得到一个也许稍微简洁的 $O(\log(r-l+1)\log n)$ 算法。
基本子串字典还有一些其他应用,例如:
问题:给定字符串 $w$,$q$ 次询问其中两个子串是否相等。
若两个子串分别是 $w[a,a+l-1]$ 和 $w[b,b+l-1]$,找到最大的 $k$ 使得 $2^k\leq l$,则两个子串相等等价于 $N_k(a)=N_k(b)$ 且 $N_k(a+l-2^k)=N_k(b+l-2^k)$。
预处理 $O(|w|\log |w|)$,查询 $O(1)$。树上扩展
基本字串字典的概念可以直接扩展到树上,只不过将“以 $x$ 为左端点长度为 $2^k$ 的子串”换成“$x$ 到其 $2^k$ 级祖先路径上边的字符拼接得到的串”,这可以由倍增算法的一种树上改造 $O(|T|\log |T|)$ 求出,其中 $|T|$ 为树的结点数。
论文中还提到了一种基于基本字串字典的求 $w$ 所有本原 $k$ 次方串的方法($k\ge 3$),但这方面的应用似乎可以被 Runs 理论全面取代,因此这里不做介绍。
例题:[Luogu P8006] String Rearrangement in Phantom
题目大意:给定字符串 $w$,$q$ 次询问,每次给定 $l_1,r_1,l_2,r_2$,求有多少个字符串三元组 $(A,B,C)$,使得 $w[l_1,r_1]=A+B+C, w[l_2,r_2]=C+\operatorname{Rev}(B)+A$。
$|w|\leq 2\times 10^5, q\leq 10^5$
题解:$A,C$ 分别可以表示成 $O(\log |w|)$ 个等差数列,枚举一对等差数列,然后考虑 $A,C$ 分别在这两个等差数列中的方案数。
设这两个等差数列分别对应的可能的 $A,C$ 为 $A_1,\ldots,A_k$,$C_1,\ldots,C_l$,长度递减排列。那么 $A_1,\ldots,A_k$ 中相邻两项的差应该是个定值($A_1$ 的长度等于最小周期的后缀),记为 $u$,同理 $C_1,\ldots,C_l$,这个差值记为 $v$。
如果 $|A_1|+|C_1|\leq len$($len$ 是给定子串的长度),那么它们的出现无交,我们只需要检查两个子串各删掉对应 $A_1,C_1$ 的部分后是否互反,以及 $u,v$ 是否互反(即 $A_1$ 的长度为 $|u|$ 的前缀和后缀是否互反,$v$ 同理)即可确定答案。
但是如果 $|A_1|+|C_1|>len$,那么上面的做法就会失效。此时,如果 $|A_3|+|C_1|\leq len$ 或者 $|A_1|+|C_3|\leq len$,那么我们可以特判 $A_1,A_2$ 或 $C_1,C_2$ 然后应用上面的方法。否则,根据引理 2(有一些细微的不同,但整体是类似的),可以知道 $A_1,\ldots,A_k$ 和 $C_1,\ldots,C_l$ 公差相同,设为 $d$。
此时,中间一整段(从 $A_k$ 结尾到 $C_l$ 开头,所有与 $B$ 的选取有关的位置)都有周期 $d$,我们任取一组总长最长的不相交的 $A_i,C_j$,如果中间的部分互反,则所有 $A_{i+k},C_{j-k}$ 也是可行的,因为中间的部分都一样。此时如果 $A_i,C_{j+1}$ 也满足中间的部分互反,说明加入一个周期不会对 $B$ 的合法性产生影响,因此这时任何一对不相交的 $A,C$ 都是合法的。
时间复杂度 $O(|w|\log |w|+q\log^2|w|)$。
4. 对称压缩 SAM / 基本子串结构
论文:徐翊轩,浅谈压缩后缀自动机,IOI 2020 集训队论文集
论文:许庭强,一类基础子串数据结构,IOI 2023 集训队论文集
基本子串结构和基本子串字典基本上是完全没有关系的两个东西。
在前置知识中我们介绍了后缀自动机。后缀自动机是接收 $w$ 所有子串的最小 DFA,那么不知大家在初学 SAM 时是否有过这样的疑问:为什么它叫后缀自动机而不是子串自动机之类的?这里我们尝试从这个问题出发,引入本节想要介绍的对称压缩 SAM 和基本子串结构。
后缀自动机的特点是每个结点代表的是一系列字符串,且它们都是其中最长者的后缀,这或许可以作为名称的由来(尽管本身可能不是这么来的)。我们换一个视角来看,SAM 是一个“向左扩展”的自动机,因为任意给定一个子串 $w[l,r]$,$w[l,r]$ 对应的 SAM 结点上的最长字符串一定是某个 $w[l’,r]$,使得 $w[l’,r]$ 与 $w[l,r]$ 的 $\operatorname{Endpos}$ 相同,且 $l’$ 最小。那么 $w[l’,r]$ 可以看成是在 $w[l,r]$ 左边反复加字符,直到再加字符会改变其出现位置(我们可以用 $\operatorname{Endpos}$ 来描述出现位置,也可以直接用出现次数来描述)。
于是我们想:有没有向右扩展的自动机呢?当然这就是反串的 SAM。那么有没有向两侧扩展的自动机呢?
- 定义:考虑串 $w$。对于任意一个 $w$ 的子串 $u$,定义 $\operatorname{occ}(u)$ 为 $u$ 在 $w$ 中的出现次数。$\operatorname{Lext}(u)$ 为最长的以 $u$ 为后缀的串 $u’$,使得 $u’$ 和 $u$ 在 $w$ 中的 $\operatorname{occ}$ 相同;$\operatorname{Rext}(u),\operatorname{Ext}(u)$ 类似,只不过定义中 $u$ 分别是 $u’$ 的前缀和子串。
首先要说明 $\operatorname{Lext},\operatorname{Rext},\operatorname{Ext}$ 是良定义的。前面已经说过了 $\operatorname{Lext}(u)$ 其实就是 $u$ 对应 SAM 结点对应的最长子串;那么同理 $\operatorname{Rext}(u)$ 相应地就是 $u$ 对应反串 SAM 结点对应的最长子串,而 $\operatorname{Ext}$ 可以看成由 $\operatorname{Lext}(u)$ 和 $\operatorname{Rext}(u)$ 拼接而成。可以直观理解为:$\operatorname{Ext}(u)$ 是每次 $u$ 出现时前后一定会连带着一起出现的那部分东西。
那么现在我们想建立一种结构,使得 $u$ 可以直接链接到 $\operatorname{Ext}(u)$,或者说把一族 $\operatorname{Ext}$ 相同的子串放到一起(例如 SAM 就是把一族 $\operatorname{Lext}$ 相同的子串放到一起)。
我们从 SAM 出发构建这一结构,SAM 已经完成了向左扩展,只需再实现向右扩展即可。对于 SAM 上的一个结点 $x$,如果其出度大于 $1$,那么它一定是不可向右扩展的,因为它右侧的内容不唯一;如果它代表的是某个后缀,那么它一定也是不可向右扩展的,因为后缀的右边没东西了。但是如果 $x$ 不代表后缀,且出度等于 $1$,那么就说明它每次出现后面接的字符是相同的(就是唯一的出度上的那个字符),这代表 $x$ 可以和它的出边指向的点 $y$ 合并,它们对应的 $\operatorname{Ext}$ 相同。重复这样的合并,就有:
- 定义:将 $w$ 的 SAM 上出度为 $1$ 且不代表后缀的结点与其出边指向的结点合并,得到的自动机称为 $w$ 的压缩后缀自动机。
注意,上面的论文中将这个东西称为“完整压缩后缀自动机”,相应地本文中的后缀树在论文中被称为“完整后缀树”,而论文中相应的“压缩后缀自动机”和“后缀树”对应的是本文中的隐式压缩后缀自动机(即把所有出度为 $1$ 的点都合并掉,不管是不是后缀)和隐式后缀树。
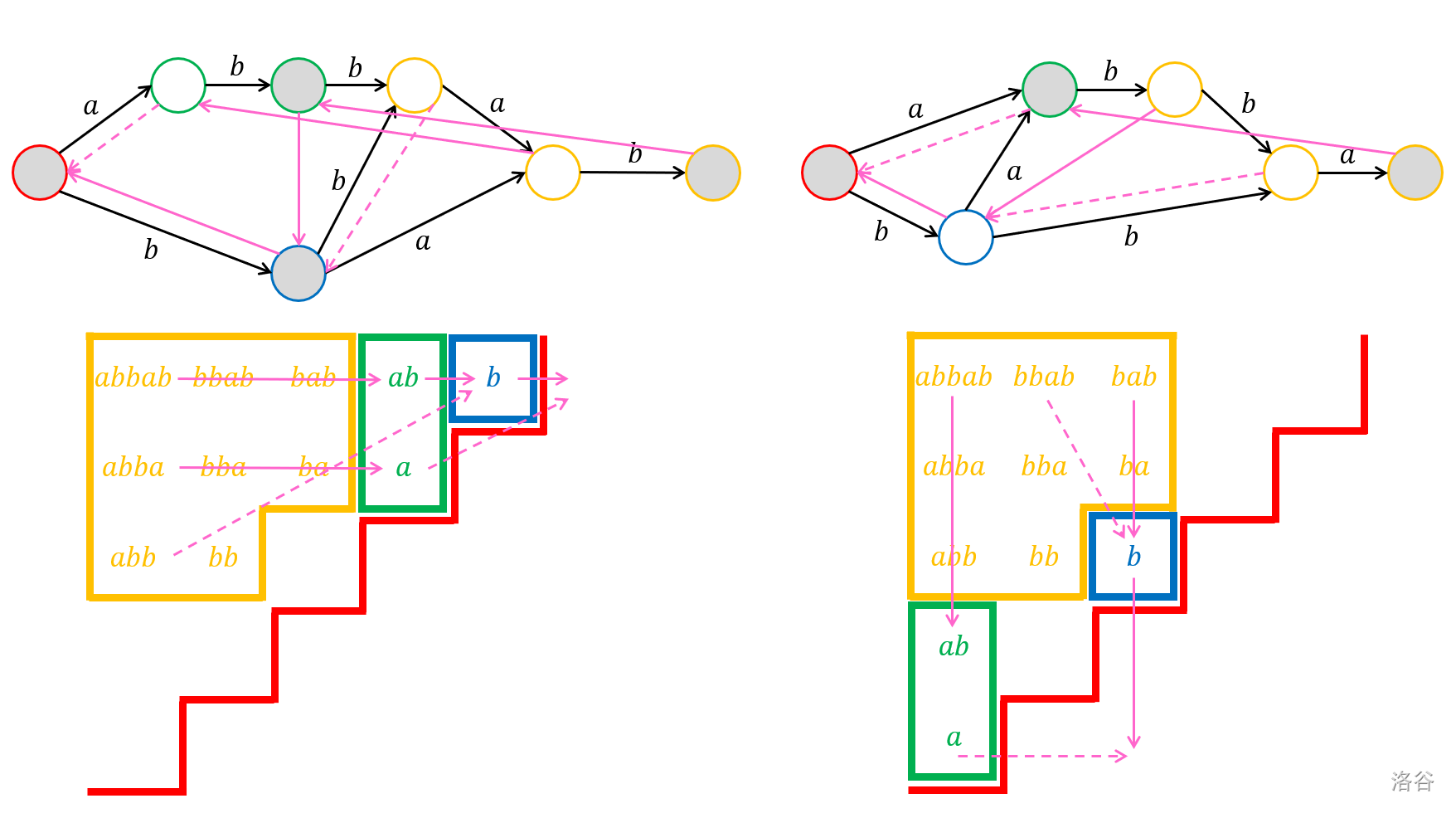
下图展示了 $\texttt{abbab}$ 和它的反串 $\texttt{babba}$ 的 SAM 和压缩 SAM,灰色结点为后缀对应的结点:
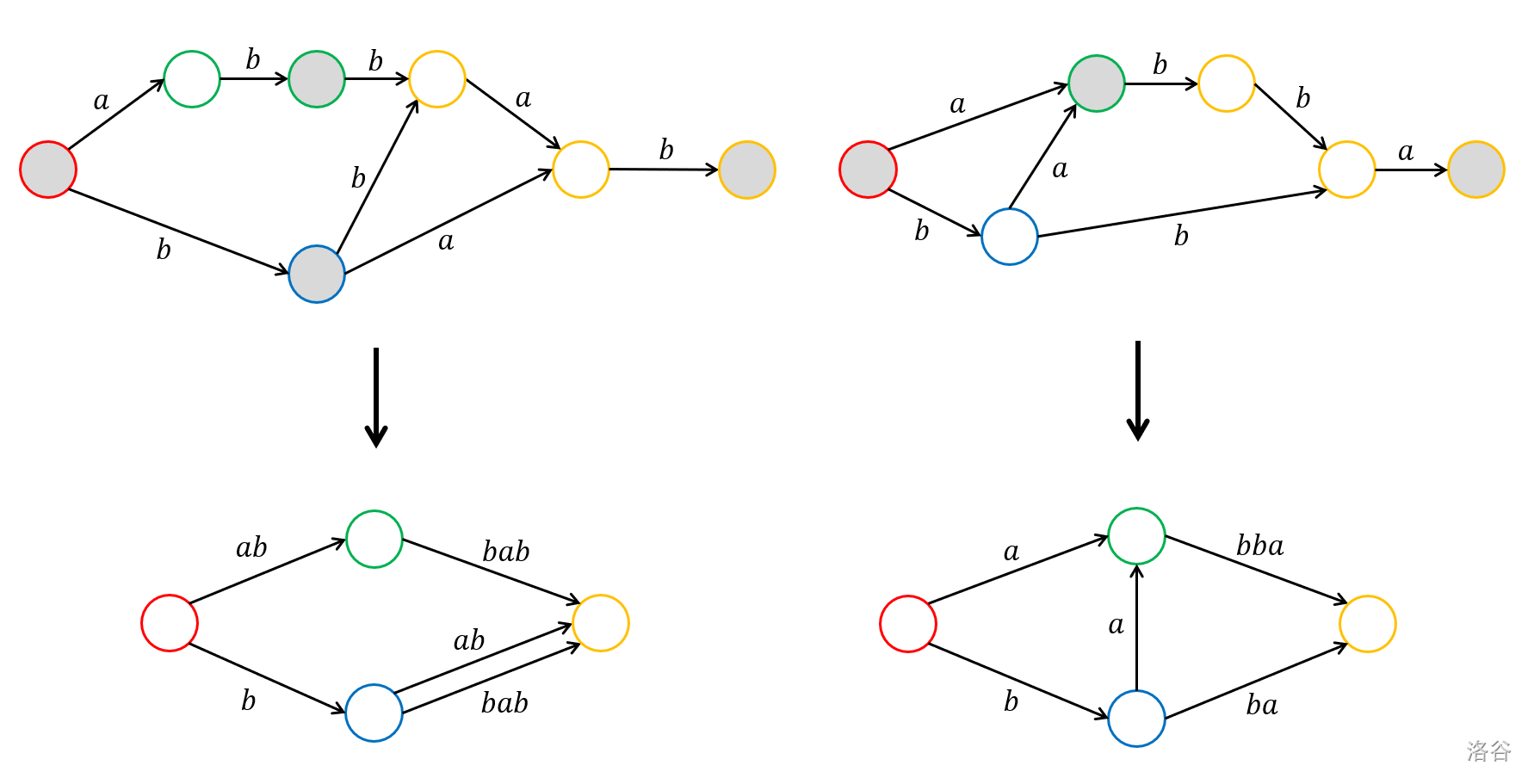
压缩 SAM 虽然是一个两侧扩展的自动机,但是它的转移边仍然是单向的——沿着转移边只能从前往后加字符。不过注意到反串 SAM 也可以压缩,并且得到的压缩 SAM 和正串压缩 SAM 应该是结点一一对应的(因为每个结点都是一个 $\operatorname{Ext}$ 等价类,而 $\operatorname{Ext}$ 和正反无关)。所以可以提出以下更有对称性的结构:
- 定义:将 $w$ 的正反 SAM 分别压缩,对应结点叠合,同时保留两个自动机上的转移,得到的结构称为 $w$ 的对称压缩后缀自动机。
对称压缩 SAM 上有两种不同类的转移,一种是向后加字符,另一种是向前加字符。因此,对称压缩 SAM 相比普通 SAM 在处理字符串问题上的优势就体现为:能够解决同时需要往左右两边加字符的问题。
对称压缩 SAM 刻画了不同的 $\operatorname{Ext}$ 等价类之间的转移关系,但是很多问题要求我们针对一个等价类内部的性质进行研究。$\operatorname{Ext}$ 等价的结构比 $\operatorname{Endpos}$ 等价这样的结构要复杂一些,下面介绍一种用来解释 $\operatorname{Ext}$ 等价类内部性质及它们之间的关系的一种字符串整体结构——基本子串结构。
我们将 $w$ 的所有子串画在一个 $|w|\times |w|$ 网格图中,横坐标表示子串的左端点,纵坐标表示右端点,然后将处于压缩 SAM 上同一结点的子串染为同种颜色,得到的结构就称之为(初步的)基本子串结构,每个同色连通块称为一个块。
下图展示了 $\texttt{abbab}$ 的正反压缩 SAM、对称压缩 SAM 和基本子串结构:
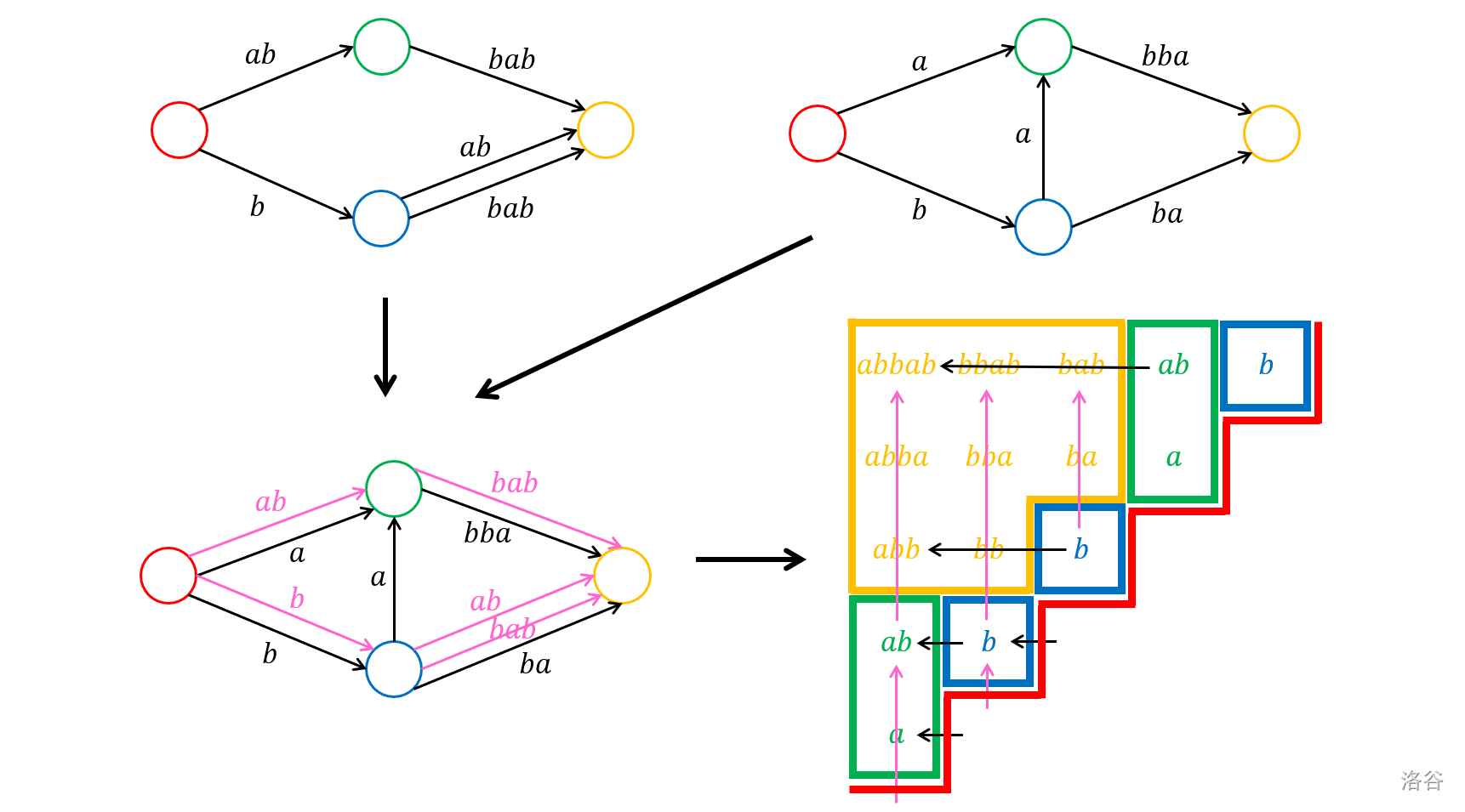
以同种颜色边框围成的区域就是一个块,本质不同的块与压缩 SAM 上的结点一一对应。而压缩 SAM 上的边即可看成横向或纵向(分别对应反串压缩 SAM 和正串压缩 SAM)相邻的两块之间的转移,这种转移关系在上图也画出来了。
根据对压缩 SAM 的讨论,我们可以得到如下结论:
结论 1:每个块是一个上端和左端对齐的阶梯形网格图,即存在 $l_a,l_b,r$ 使得这一块中的所有格子恰为 $\{(x,y)\mid l_a\leq x\leq l_b, f(l_a)\leq y\leq r\}$,其中 $f$ 单调不降。
证明:首先我们说明一个块是上端和左端对齐的,即上边界和左边界不会是凹的,即如果存在两个子串 $w[l_1,r_1]$ 和 $w[l_2,r_2]$ 属于同一块,则 $w[\min(l_1,l_2),\max(r_1,r_2)]$ 也属于这一块。这很容易说明,只要考虑 $\operatorname{Ext}$ 即可,这些串的 $\operatorname{Ext}$ 都是相同的。
再说明它确实是阶梯型网格图。现在我们已经知道块有一个左上顶点,即所有块中串的 $\operatorname{Ext}$,记这个极长的串为 $w[l,r]$。我们只需说明如果 $\operatorname{Ext}(w[l’,r’])=w[l,r] ([l’,r’]\subset [l,r])$ 则 $\operatorname{Ext}(w[l’-1,r’])=w[l,r] (l’>l)$ 和 $\operatorname{Ext}(w[l’,r’+1])=w[l,r] (r’<r)$ 即可,这由 $\operatorname{Ext}$ 的定义可以直接得到。
于是,对于一个块 $C$,可以定义其左上角的格子对应的串为其代表元 $\operatorname{Rep}(C)$。
结论 2:每个串出现且只出现在一种块中,且在块中只出现了一次,每种本质不同的块 $C$ 恰好出现了 $\operatorname{occ}(\operatorname{Rep}(C))$ 次。
证明:每个串显然只能出现在一种块中,因为其 $\operatorname{Ext}$ 是唯一的。$\operatorname{Rep}(C)$ 在 $C$ 中只出现了一次,而它在整个串中出现了 $\operatorname{occ}(\operatorname{Rep}(C))$ 次,所以 $C$ 就出现了 $\operatorname{occ}(\operatorname{Rep}(C))$ 次,而 $C$ 中的其他串也出现了 $\operatorname{occ}(\operatorname{Rep}(C))$ 次,所以它们不可能在 $C$ 中出现两次或以上(否则总次数就不对了)。
对于一个块 $C$,定义 $h(C)$ 为其左边界的高度,$w(C)$ 为其上边界的宽度。
结论 3:一块中的一行对应一个 $\operatorname{Endpos}$ 等价类,从而对应一个 SAM 结点;一列对应一个 $\operatorname{Startpos}$ 等价类,从而对应一个反串 SAM 结点。
证明:以结论前半部分为例。根据 SAM 部分中讲过的内容,一个 $\operatorname{Endpos}$ 等价类一定是网格图上某一行的一个连续段。一块中的一行 $\operatorname{Endpos}$ 一定相同,且如果往两边扩展则 $\operatorname{occ}$ 都不同,$\operatorname{Endpos}$ 肯定不会相同,所以又不能扩展,从而就是一个 $\operatorname{Endpos}$ 等价类。
结论 4:$\sum_C h(C)+w(C)=O(|w|)$,其中求和是对本质不同的块求和。
证明:由结论 3,每个 SAM 结点会为 $\sum_C h(C)$ 贡献 $1$,每个反串 SAM 结点会为 $\sum_C w(C)$ 贡献 $1$,由 SAM 结点数的结论知 $\sum_C h(C)+w(C)=O(|w|)$。
有了结论 3,我们还可以进一步研究 SAM 上的后缀链接对应到基本子串结构上的结果。根据上面的对应,SAM 上的后缀链接就发生在横向相邻的两块的交界处,反串 SAM 上的后缀链接就发生在纵向相邻的两块的交界处。
结论 4 是很多算法复杂度的保证。例如,如果在每一块上有一个 $O((h(C)+w(C))\operatorname{polylog}(h(C)+w(C)))$ 的算法,则对每一块做一遍的话,这个算法的复杂度就是 $O(|w|\operatorname{polylog} |w|)$。
之前我们介绍了用基本子串字典处理区间 Border 的方法,而基本子串结构给了另一种看待区间 Border 问题的视角。
子串 $w[l,r]$ 的 Border 即同时为它的前缀和后缀的串的集合,而这相当于是 $w[l,r]$ 在正串 SAM 上的链接树祖先链与反串 SAM 上的链接树祖先链的交。现在让我们考虑对两棵链接树都进行重链剖分,然后我们按照这种重链剖分来确定一种特定的每个块在网格图上的位置。我们知道每个块在网格中出现了多次,我们希望给每个块选择其中一个它出现的位置,使得所有重链上的后缀链接都是直接的,即都是同一行/列的两块之间的转移。
这(给块选位置)对于后续的算法并不是必要的,但它能直观地告诉我们一些性质,所以下面我们递归地给出一种构造,以正串 SAM 的链接树为例:从叶子出发,叶子的出现次数当然都是 $1$,它们的位置确定。对于每个非叶结点,将它安放在它的重儿子放在的位置的右侧(不难发现一个块中所有 SAM 结点对应的重儿子可以认为都来自同一块,事实上同一块中所有 SAM 结点对应的子树是完全同构的)。
下图展示了 $\texttt{abbab}$ 的正反串 SAM 链接树的重链剖分和对应的基本子串结构中块的位置,可以看到,重边都是横平竖直的。
对于正串 SAM 链接树上一条重链,令其编号为其叶结点所在的行;对于反串,则是叶结点所在列。
结论 5:同一个块中,所有正(反)串 SAM 结点对应的正(反)串 SAM 链接树上重链编号连续。
证明:因为在一条重链上,所以每个结点与其重链上的叶子在同一行(列),根据编号的定义知道是连续的。
下面我们回到区间 Border 问题,现在问题已经转化为寻找两棵树上两个祖先链的交,我们先把祖先链转化为 $O(\log |w|)$ 条重链段,虽然两条祖先链就会有 $O(\log^2 |w|)$ 个重链对,但是显然只有其中 $O(\log |w|)$ 对可能会相交(因为相交至少要长度相等,然后可以双指针一下),我们分别考虑每一对。
考虑每个正串 SAM 上的点,它对应的是基本子串结构某个块的一行,于是其中所有串就属于这一块中的不同的列,根据结论 5,这些列对应的反串 SAM 结点所在重链编号连续,所以每个正串 SAM 结点对应的是一个反串 SAM 重链编号的区间,而我们要查询的就是正串 SAM 某条重链上有多少个点对应的区间包含某个给定的反串重链。
但是注意我们考虑的并不是一整条重链,而只是重链的一个前缀(靠近根的部分),这可以通过加上一维长度来限制,即我们所求的是正串 SAM 一条重链和反串 SAM 一条重链的交集中长度 $\leq l$ 的那部分。于是我们把上面的对应关系扩展一下,每个正串 SAM 结点对应的是一个反串 SAM 重链编号、长度为坐标轴的二维平面中,一条斜率为 $1$ 的斜线段。
以区间 Border 计数为例,对于每条正串 SAM 重链,它对应的数据结构问题可以描述为:给定二维平面中若干个斜率为 $1$ 的斜线段,若干次询问一条平行于 $y$ 轴的直线段与多少个斜线段有交,这可以简单地转化为一个二维数点。从而我们用基本子串结构也解决了区间 Border 问题,但复杂度相比基本子串字典多个 $\log$(因为每个询问要进行 $O(\log |w|)$ 次二维数点询问)。
例题:[SDOI / SXOI 2022] 子串统计
题目大意:给定一个字符串 $w$,令 $T_0=w$,$T_i$ 是在 $T_{i-1}$ 的基础上删除第一个或最后一个字符得到的串,最后 $T_{n-1}$ 是一个只包含一个字符的串。总共有 $2^{n-1}$ 种删除方案(尽管得到的 $T$ 序列可能有一些是相同的),每种方案的权值定义为 $\prod_{i=0}^{n-1}\operatorname{occ}(T_i)$,求所有方案的权值和对 $998244353$ 取模。
$|w|\leq 10^5$
题解:每种方案可以看成是一条在基本子串结构上从左上角走到反对角线 $x=y$ 上任何一个点的只能往右或往下走的路径,我们要对所有路径上的点权乘积求和,由于权值用 $\operatorname{occ}$ 定义,所以同一块内所有点的权值相同。不妨把路径反过来,变成从对角线上的任何一个点走回到左上角。
我们单独考虑一块,如果路径经过这一块,那么一定是从这一块的右下轮廓上某个点出发,走到左上边界的某个点,而这部分的贡献是可以用一个经典的分治 NTT 算出,所以只要(按照从右下到左上的顺序)对每一块都算一遍贡献即可,相邻块之间的贡献可以在边界处(即正反 SAM 后缀链接)转移。
对某一块 $C$ 算的复杂度是 $O((h(C)+w(C))\log^2(h(C)+w(C)))$,所以总复杂度 $O(|w|\log^2 |w|)$。
例题:[数据删除]
稍后公布。
5. Lyndon 分解 / Significant Suffix
论文:万成章,浅谈与 Lyndon 理论有关的字符串组合问题,IOI 2022 集训队论文集
Lyndon 理论是用来解决与字典序相关的问题的一套理论,不过在代数上它似乎有别的用处,但这和本文无关。
- 定义:如果一个串 $w$ 满足它小于它的所有非空真后缀,即 $\forall i\in [2,|w|], w<w[i,|w|]$,则称 $w$ 是一个 Lyndon 串。
由于 $w$ 一定比它的后缀长,所以对于 Lyndon 串 $w$ 必然有 $w\lhd w[i,|w|]$。
再介绍一个和 Lyndon 串有关的概念。对于字符串 $w$,形如 $w[i,|w|]+w[1,i-1] (i\in [1,|w|])$ 的串称为 $w$ 的一个循环表示,如果 $w$ 是其所有循环表示中最小的,则称 $w$ 是一个 Necklace(项链)。
- 定义:如果一个串 $w$ 满足存在一个 Lyndon 串 $u$ 使得 $w=u^ku’$,其中 $u’$ 是 $u$ 的真前缀,则称 $w$ 是一个近似 Lyndon 串。
对于字符串 $w$,如果存在一系列 Lyndon 串 $w_1,\ldots,w_k$ 满足 $w_i\ge w_{i+1}$ 且 $w=w_1+w_2+\ldots +w_k$,则称 $w=w_1+w_2+\ldots w_k$ 是 $w$ 的 Lyndon 分解,每个 $w_i$ 为 $w$ 的一个 Lyndon 因子。
我们下面证明,一个串 $w$ 的 Lyndon 分解是存在且唯一的。
引理 1:若 $u,v$ 都是 Lyndon 串且 $u<v$,则 $uv$ 是 Lyndon 串。
证明:如果 $u\sqsubset v$ 则由 $v$ 是 Lyndon 串知 $uv<v$;如果 $u\lhd v$ 则显然 $uv<v$。故无论如何 $uv<v$。
对于 $v$ 的非空后缀 $v’$,有 $uv<v\leq v’$,对于 $u$ 的非空真后缀 $u’$,有 $u\lhd u’\to uv\lhd u’v$,因此 $uv$ 小于它的所有非空真后缀,即 $uv$ 是 Lyndon 串。
引理 2:若 $w=w_1+\ldots +w_k$ 是 $w$ 的 Lyndon 分解,则 $w$ 的最小非空真后缀为 $w_k$。
证明:设 $w$ 的最小非空真后缀为 $u=u’w_i\ldots w_k$,其中 $u’$ 是 $w_{i-1}$ 的非空后缀,则 $u\ge u’\ge w_{i-1}\ge w_k$,而 $w_k$ 是一个后缀,所以 $u$ 只能等于 $w_k$。
根据引理 1 可以说明 Lyndon 分解的存在性:初始时令每个字符都是一个 Lyndon 因子,然后不断合并相邻的满足 $w_i<w_{i+1}$ 的 Lyndon 因子 $w_i,w_{i+1}$,最后就得到了一个 Lyndon 分解(在下一节中,我们将给出一个以此为基础的 Lyndon 分解算法)。
根据引理 2 可以说明 Lyndon 分解的唯一性:最后一个 Lyndon 因子总是最小非空真后缀,删掉它后递归即可。至此我们成功证明了 Lyndon 分解是唯一存在的。
我们可以将 Lyndon 分解中相邻相同的 Lyndon 因子写在一起,成为 $w=w_1^{p_1}\ldots w_k^{p_k}$ 的形式,其中 $w_1>w_2>\ldots >w_k$。
Duval 算法:$O(|w|)$ 地求出 $w$ 的 Lyndon 分解。
从前往后依次加入 $w$ 的每个字符,一边加一边分解。设当前加入到字符 $w[i]$,我们维护当前前缀一个还没有被分解的后缀 $w[j,i]$,我们时刻保证这个后缀是一个近似 Lyndon 串,对应的 Lyndon 串长度为 $k$,即设 $u=w[j,j+k-1]$,$u$ 是一个 Lyndon 串且 $w[j,i]=u^tu’$,$u’$ 是 $u$ 的真前缀。现在我们加入字符 $w[i+1]$:
若 $w[i+1]=w[i+1-k]$,则自然延续近似 Lyndon 串即可;
若 $w[i+1]>w[i+1-k]$,则此时 $w[j,i+1]$ 本身是一个 Lyndon 串了,所以我们令 $k\leftarrow i-j+2$。
若 $w[i+1]<w[i+1-k]$,则 $w[j,i+1]$ 不再是一个近似 Lyndon 串,我们将 $w[j,j+k-1],w[j+k,j+2k-1],\ldots$ 这些 Lyndon 串分解出来(它们是相等的),作为 $w$ 的 Lyndon 因子,直到 $j+pk-1\ge i+1$。令新的 $j$ 为 $j+(p-1)k$,然后将 $i$ 回滚至 $j$,$k\leftarrow 1$,重新加入一遍 $w[j],\ldots,w[i]$ 这些字符,加入过程同上。
若所有字符都加入完毕了,则类似上面最后一种情况,把当前近似 Lyndon 串 $w[j,|w|]$ 的 Lyndon 前缀 $w[j,j+k-1],w[j+k,j+2k-1],\ldots$ 分解出来,然后将 $i$ 回滚到最后余下一段的开头再加一遍。
Duval 算法的正确性可以直接验证——它分解出的每个子串确实都是 Lyndon 串,且字典序确实递减。
Duval 算法的复杂度不难证明。每当分解出一段 Lyndon 因子 $w_i^{p_i}$ 时,$i$ 会回滚 $w$ 的一个前缀,从而回滚的总长度不超过 $\sum |w_i|$,从而不超过 $|w|$,因此 $i$ 前进的次数也是 $O(|w|)$,每次前进可以 $O(1)$ 完成判断,而分解的总复杂度是 $O(|w|)$,所以整个算法的复杂度为 $O(|w|)$。
- 定义:如果 $w$ 的一个后缀 $w’$ 满足:存在一个 $v$ 使得对于 $w$ 的任何后缀 $w’’$ 都有 $w’v\leq w’’v$,则称 $w’$ 是 $w$ 的一个 Significant Suffix。$w$ 的所有 Significant Suffix 的集合记为 $\operatorname{SS}(w)$。
Significant Suffix 有一个性质:如果 $w’\in \operatorname{SS}(w)$,那么不存在另一个后缀 $w’’$ 使得 $w’’\lhd w’$ 的那些后缀 $w’$,这是比较好理解的:$w’’\lhd w’$ 可以推出 $w’’v\lhd w’v$。
一些与字典序相关的问题可以归于对 Significant Suffix 的讨论,所以我们首先介绍其一些性质。
引理 3:如果 $v,uv,u^2v (u\neq \varepsilon)$ 都是 $w$ 的后缀,则 $uv\notin \operatorname{SS}(w)$。
证明:事实上我们有 $uvy<vy\iff u^2vy<uvy$,所以 $uvy$ 总不是最小的。
设 $w$ 的分解为 $w=w_1^{p_1}w_2^{p_2}\ldots w_k^{p_k}$,以下引理揭示了 Lyndon 分解与 Significant Suffix 的联系:
引理 4:$w$ 的 Significant Suffix 一定形如 $w_i^{p_i}\ldots w_k^{p_k}$,将这个串记为 $s_i$。
证明:第一步说明 Significant Suffix 形如 $w_i^t\ldots w_k^{p_k}$。考虑形如 $uw_i^t\ldots w_k^{p_k}$ 的后缀,其中 $u$ 是 $w_i$ 的真后缀,则 $w_i\lhd u$,故 $w_i^{t+1}\ldots w_k^{p_k}\lhd uw_i^t\ldots w_k^{p_k}$,这说明了以 $u$ 开头的这个后缀不是 Significant Suffix。
第二步说明上述形式中一定有 $t=p_i$,若 $0<t\ne p_i$,则考虑 $w_i^{t-1}\ldots w_k^{p_k}, w_i^t\ldots w_k^{p_k}, w_i^{t+1}\ldots w_k^{p_k}$ 这三个后缀,形成了引理 3 中 $v,uv,u^2v$ 的形式,于是其中的 $w_i^t\ldots w_k^{p_k}$ 就不是 Significant Suffix。
设 $\operatorname{SS}(w)$ 从短到长排序为 $u_1,\ldots,u_t$,那么对于任意 $i,j$ 都不能有 $u_i\lhd u_j$ 或 $u_j\lhd u_i$,从而只能 $u_1\sqsubset u_2\sqsubset \ldots \sqsubset u_t$。
现在考虑 $s_1,\ldots,s_k$(在引理 4 中定义)中哪些可能成为 Significant Suffix,根据上面的讨论,一个必要条件显然是 $s_{i+1}\sqsubset s_i$。
引理 5:$s_{i+1}\sqsubset s_i\iff s_{i+1}\sqsubset w_i\iff i\ge \lambda$,其中 $s_\lambda$ 为 Duval 算法第一次比较完 $w$ 的末尾时的近似 Lyndon 串。
证明:如果 $i<\lambda$,说明 Duval 算法过程中某一时刻近似 Lyndon 串为 $w_i^{p_i}w’$ 且下一个字符为 $c$,其中 $w’$ 是 $w_i$ 的真前缀,$c>w_i[|w’|+1]$,这说明 $w_i\lhd s_{i+1}$,从而 $s_{i+1}\not\sqsubset s_i, s_{i+1}\not\sqsubset w_i$。
如果 $i=\lambda$,则 $s_i$ 是近似 Lyndon 串,同时根据 Duval 算法的规则可知 $s_{i+1}\sqsubset w_i$,于是 $s_{i+1}\sqsubset s_i$,同时 Lyndon 串的前缀一定是近似 Lyndon 串,所以 $s_{i+1}$ 也是近似 Lyndon 串,于是对于 $i>\lambda$ 的情况可以归纳。
于是我们说明了 Significant Suffix 只会在 $s_\lambda,\ldots,s_k$ 中诞生(事实上,它们全都是 Significant Suffix,但这通常不很关键),我们由此分析一下 $|\operatorname{SS}(w)|$:由引理 5 知 $s_{i+1}\sqsubset w_i$,从而,$|s_i|>2|s_{i+1}|$,所以 $|s_\lambda|>2^{k-\lambda}|s_k|$,而 $|s_\lambda|\leq |w|$,所以 $k-\lambda< \log_2(|w|)$,于是:
- 结论 1:$|\operatorname{SS}(w)|=O(\log |w|)$,且较长的 Significant Suffix 长度大于较短的 Significant Suffix 的长度的两倍。
现在让我们回答一个基本的问题:给定 $v$,求最小的 $w’v$,其中 $w’$ 是 $w$ 的后缀,将答案记为 $\operatorname{Minsuf}(w,v)$。为此,我们首先引入一个比较规则:
引理 6:$uv<v\iff u^{\infty}<v$
证明:设 $v=u^tu’s$,其中 $u’$ 是 $u$ 的真前缀,$s=\varepsilon$ 或 $s[1]\ne u[|u’|+1]$。若 $s=\varepsilon$,则 $v\sqsubset uv$ 且 $v\sqsubset u^{\infty}$;若 $s[1]>u[|u’|+1]$,则 $uv\lhd v$ 且 $u^{\infty}\lhd v$;若 $s[1]<u[|u’|+1]$,则 $v\lhd uv$ 且 $v\lhd u^{\infty}$。无论如何,结论都成立。
对于 $i\ge \lambda$,我们知道 $s_{i+1}\sqsubset w_i$。因此设 $w_i=s_{i+1}y_i$(令 $s_{k+1}=\varepsilon$),再设 $x_i=y_is_{i+1}$,那么有 $s_i=s_{i+1}x_i^{p_i}$。现在我们想知道哪个 $s_iv$ 是最小的,那么可以比较一下 $s_iv$ 和 $s_{i+1}v$,去掉公共前缀 $s_{i+1}$ 后就是要比较 $x_i^{p_i}v$ 和 $v$。由引理 6,我们知道 $x_i^{p_i}v<v\iff x_i^{\infty}<v$。
引理 7:$x_i^{\infty}>x_{i+1}^{\infty}$。
证明:显然 $x_i^{\infty}>y_i$,只需证明 $y_i>x_{i+1}^{\infty}$ 即可。在两边前面都加上一个 $s_{i+1}$,等价于要证 $s_{i+1}y_i>s_{i+1}x_{i+1}^{\infty}$,而 $s_{i+1}y_i=w_i, s_{i+1}x_{i+1}^{\infty}=w_{i+1}^{\infty}$,由 $w_i$ 是 Lyndon 串以及 $w_{i+1}\sqsubset w_i$ 知 $w_i>w_{i+1}w_i$(考虑删去一个公共前缀 $w_{i+1}$),于是由引理 6 知 $w_i>w_{i+1}^{\infty}$,至此命题得证。
因此只要我们找到一个 $x_{i-1}^{\infty}>v>x_i^{\infty}$,那么对于所有 $\lambda\leq j\leq i-1$ 都有 $x_j^{\infty}>v$,对于所有 $i\leq j\leq k$ 都有 $x_j^{\infty}<v$,于是我们就有:
- 结论 $2$:$\operatorname{SS}(w)=\{s_\lambda,\ldots,s_k\}$,且:$\operatorname{Minsuf}(w,v)=\begin{cases}s_\lambda v & v>x_\lambda^{\infty} \ s_iv & x_{i-1}^{\infty}>v>x_i^{\infty} \ v & x_k^{\infty}>v\end{cases}$。
许多字典序相关问题都可以转化为求 $\operatorname{Minsuf}(w,v)$,例如最小后缀就是 $v=\varepsilon$;最大后缀就是字典序取反后 $v=\texttt{z}$($\texttt{z}$ 是一个极大字符);最小循环表示就是 $v=w$。
例题:[ZJOI 2017] 字符串
题目大意:维护一个长度为 $n$ 的字符串(数字序列)$w$,支持 $q$ 次操作:区间加,求区间最小后缀。
$n\leq 2\times 10^5, q\leq 30000$
题解:既然有区间加这样的操作,自然尝试用线段树维护 $w$。不过现在关键的问题是我们无法直接从左右两边的最小后缀合并得到它们拼接后的最小后缀,不过如果我们维护了两边的所有 Significant Suffix,就可以进行合并了。
如果我们已知 $\operatorname{SS}(u)$ 和 $\operatorname{SS}(v)$,并且 $|v|\ge |u|$,那么根据上面的结论 1,$\operatorname{SS}(u)$ 中只有至多一个能够被选进 $\operatorname{SS}(uv)$,唯一的候选者自然就是 $\operatorname{Minsuf}(u,v)$。由于多算一些串进 $\operatorname{SS}(uv)$ 其实并没有关系(只要数量仍然是 $O(\log |uv|)$ 就行),所以我们就将 $\operatorname{SS}(v)\cup \{\operatorname{Minsuf}(u,v)\}$ 看作 $\operatorname{SS}(uv)$。从而我们可以在线段树上维护每个点对应子串的 Significant Suffix 集合(尽管可能多算一些串),如果查询两个子串大小关系的复杂度为 $O(\log n)$ 的话,一次 pushup 的复杂度就是 $O(\log^2 n)$。
查询时,只需要找到所有拆分出的线段树上的结点的所有 Significant Suffix 并选一个最小的即可,复杂度为 $O(\log^3 n)$。
考虑如何实现 $O(\log n)$ 比较两个子串大小关系。可以以修改的时间代价换查询的时间代价,采用分块,维护每个点到块末尾的哈希值和块端点到末尾的哈希值,即可 $O(\sqrt n)$ 修改,$O(1)$ 求出子串哈希值,从而套一个二分就能 $O(\log n)$ 查询子串 LCP 和比较子串大小。
复杂度为 $O(n\log^2 n+q(\log^3 n+\sqrt n))$,如果用线段树替代分块则为 $O(n\log^2 n+q\log^4 n)$。
例题:[数据删除]
稍后公布。
例题:[数据删除]
稍后公布。
6. 幂串 / Runs
7. 杂技
广义 SAM
SAM 上的 DAG 剖分
回文串
Lyndon 计数问题